Data Recovery Cases Spark Solves
What kinds of cases does Spark help with? How is it different from software-only data recovery tools? When does hardware data recovery equipment perform better than software? To help answer these questions we will outline the most common hard drive failure symptoms, explain what each symptom usually means, and show how it will be handled by our hardware and software solution in comparison with software-only tools. We split the symptoms into three categories:
High Recoverability
Drive spins up and identifies correctly, but recovering it with software tools works too slowly to be practical.
Software applications do not have the necessary control over the drive to do any kind of read instability handling. As a
result, every read command that falls on a bad sector takes 4-20+ seconds to process, during which time the drive causes
further damage to itself. It’s not a problem if there are a few bad sectors, but if there are a lot then the recovery
will take too long and the drive will crash before it can be recovered.
Spark automatically uses reset commands to abort bad sector processing, effectively skipping bad sectors within a second
in most cases. This allows the recovery to proceed much faster and the drive to degrade much slower, allowing for more difficult cases to be solved.
Software: Waiting forever, hoping the drive responds
If a read command falls on a bad sector, it will be handled by layers of system software (BIOS/OS) that the software application can’t possibly control. The best-case scenario is that the computer waits without crashing until the drive responds to the read command on its own. Every time the read command falls on a bad sector, the drive will spend somewhere from 4 seconds to over 20 seconds making hundreds of failed read attempts, then conclude the sector is bad, write to its firmware area (located on the platters) to update various logs, and finally respond with an error message, at which point the software application can send the next read command. This process wastes time, quickly causes further physical degradation of the drive, and risks firmware corruption.
Spark: Quickly skipping bad sectors with resets
Spark’s proprietary ATA controller automatically stops bad sector processing. If a drive does not respond to a read command within a fraction of a second, Spark automatically uses different hardware resets (such as COM reset, PHY reset, etc.) as needed to force the drive to stop working on it. This alone eliminates the large majority of useless processing, and in most cases also stops the drive from registering bad sectors in its firmware logs. This decreases the amount of damage that the drive takes during recovery, usually allowing for enough data to be recovered before the drive completely crashes. If a serious internal exception causes the drive to stop responding to all commands, with Power Control Add-on Spark will automatically repower it to continue the recovery process without user input.
Drive spins up and identifies correctly, but accessing it causes a crash/freeze/restart/blue screen at some point during the recovery process.
Standard computers are designed with overall system stability as the main goal. To operate reliably and predictably, generic
hardware and system software (BIOS/OS) work with drives only within the strict confines of the standard ATA protocol.
Degraded drives can fail to abide by ATA protocol rules, thereby causing a crash, freeze, reboot, connection drop, or
other similar issues in standard computers.
Spark’s hardware, firmware, and software are all specifically built to handle
a wide range of different situations and will not crash as a result of unexpected operation from the drive.
Software: Indirect access causes big problems
Software data recovery applications do not have direct control of or exclusive access to the drive. They can only send read commands to the OS API. This will only work if the communication attempt passes through each layer of system software without any issues, and the drive is capable of consistently processing read commands.
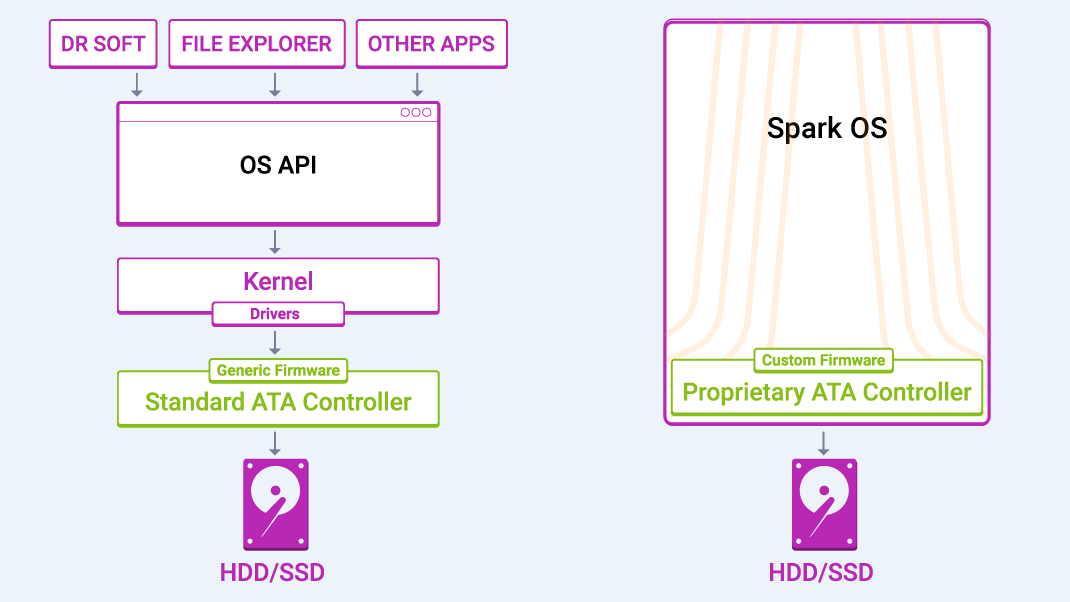
But if the drive isn’t operating as expected, communication can break down at any point. If the drive is responding with errors, any of the system software layers could have an exception and crash the PC. If the drive has an internal exception when processing a bad sector — for example, while updating firmware logs — it may not respond within a reasonable time, which would also cause the computer to freeze, restart, or drop the connection to the drive. To make matters worse, because the software application has no direct connection to the drive, it may not even be aware when the connection has been dropped. In that case, it will keep trying to recover data, but none of its attempts will actually go through, leaving the drive to idle and do further harm to itself.
Spark: Exclusive drive access and control
Spark has direct control of and exclusive access to drives. At every step of the recovery process, it uses proprietary software, firmware, and hardware designed specifically to handle degraded drives, so it will not crash unexpectedly.
Drive spins up and identifies correctly in BIOS, but does not identify in device manager within OS.
This usually happens due to bad sectors within critical file system metadata. Standard operating systems have no way of dealing
with that and will fail to identify drives with this issue.
Spark is designed to handle this situation and will usually
be able to load a file tree and go after specific files, despite bad sectors within critical file system metadata. If
too many file system metadata areas are inaccessible or have been overwritten (for example due to an accidental format)
then Spark can be used to take a full image of the drive, handling read instability and firmware issues in the process.
Afterwards, R-Studio can be used to scan this image to recover the files.
Software: Limited to drives visible by the OS
The standard file system mounting process will automatically begin as soon as a drive is connected to Windows or MacOS. While mounting the drive, the operating system will reach the first unreadable block within critical file system metadata, attempt to read it a number of times, and if it’s not successful then it will either give up (MacOS), or restart mounting from the beginning (Windows). Mounting will fail like this even if the contents of the unreadable block are not necessary to mount the drive. Standard operating systems do not work with blocks smaller than 8, so even if just 1 sector is bad, the entire 8 sector block it belongs to will be missed and the drive will not be mounted. If the mounting process fails to complete then the drive will remain invisible to the operating system.
Spark: Intelligent file system parsing
Spark loads the file system in an entirely different manner. First it will clone as much file system metadata as possible to the image file, including every good sector within every unreadable block. From there it will work only with the image to parse the file system and build a file tree. Occasional bad sectors within file system metadata will not be an issue, provided they do not restrict access to data which is strictly necessary to load the file tree. Some file system elements have multiple copies, which will be located and used automatically in place of elements that have bad sectors. This process allows Spark to successfully load the file tree and recover the files in the majority of such cases. Even if the file tree can’t be loaded due to severe logical corruption, Spark can still be used to take a full image of the drive, after which R-Studio can be used to recover the files from this image.
Bad sectors are leaving too many files corrupted or lost.
Software tools usually read data in large blocks of sectors and do not retry failed blocks sector by sector, which leaves
many good sectors unread, corrupting a larger number of files. Furthermore, there is usually no validation of file integrity,
leaving the user in the dark about the quality of their recovery.
Spark can retry failed blocks sector by sector, ensuring
recovery of every good sector within every bad block, thereby decreasing the level of corruption in files. Spark can
also identify exactly which files have bad sectors in them, so you know which files are integral and which ones are corrupt.
Software: Slow and imprecise
Software data recovery tools usually read data in large blocks of sectors (512-4,096) and do not retry failed blocks one sector at a time. If a hard drive cannot read every single sector from the requested block, the whole read request will fail and nothing will be recovered, even if most of the sectors in the block are perfectly healthy. This leads to losses of thousands of good sectors, introducing corruption to a larger number of files.
Spark: Faster, with more data
Because Spark uses a live sector map, blocks that fail to read on the first pass can be easily retried one sector at a time to ensure that all good sectors within each unreadable block are recovered. This sector map is also used to validate file integrity, showing which files are corrupt (contain bad sectors) and which files are integral. An efficient architecture and the ability to quickly stop bad sector processing has a substantial impact — Spark can often dig into an entire unreadable block one sector at a time before a software tool finishes waiting on a single failed read command.
Spark in action
This animation is a great overview of the concepts we covered up to this point, showing how Spark and software applications recover the same unstable drive. We are assuming the software application was able to correctly identify the drive and that every layer of the architecture involved in communicating with the drive is working flawlessly. In other words, it is a comparison between the absolute best-case scenario for software applications and an average case for Spark. It is slowed down by 3 times to make it easier to understand:
Medium recoverability
Drive spins up and sounds normal, but is not identified in the BIOS of a standard computer.
This is a very broad symptom that can be caused by almost any issue: general instabilities, firmware failure, electronic failure, and/or mechanical failure. Spark will help if the problem is with general instabilities, or common types of firmware failures. If the drive suffered mechanical or electronic failure then some part swaps will be necessary as a step in the recovery process. Our support team would be happy to help solve electronic issues by guiding a swap of the printed circuit board from a donor drive. If the drive suffered complex firmware or mechanical failure, it will have to be handled by a professional with strong understanding of hard drive design.
Software: Limited to the most complex drive initialization process
To begin working with drives, standard computers send a large number of initialization commands, such as Set UDMA Transfer Mode, Initialize S.M.A.R.T., Initialize Device, Recalibrate, and so on. If a drive is degraded, it may fail to respond to all of these commands within the expected time, which usually leads to a failure to identify the drive. This doesn’t mean the drive has actually failed, or even that it has any serious problems — it’s just that its degraded firmware subsystem has failed to process one of these initializations commands in the exact way it was expected to. Furthermore, most of these initialization commands are unnecessary for modern hard drives and only create a potential for problematic behavior. They are a part of the initialization process in standard computers because they are necessary for older drives. Standard computers do not make any distinction between older and newer drives, and instead always use the most complex initialization process to support the largest number of drives, which causes some degraded, but still functional drives to remain unidentified.
Spark Hardware: Keeping it simple
Spark uses the lightest initialization procedure in each case, which for most modern drives is a single Disk Identification command. Spark is also built to be forgiving of possible deviations in the drive’s response, ensuring that there are no unexpected problems and that only truly failed drives are unidentified.
Drive spins up and identifies correctly, but makes clicking/grinding noises and locks up the PC while attempting to read data.
Hard drives with this symptom have advanced physical degradation and could easily crash completely at any moment. In the majority of such cases physical damage is isolated to particular heads/platters. With Pro Add-on Spark can identify and disable failed heads to achieve a partial recovery from good heads/platters. If the damage is spread out evenly then due to early termination of bad sector processing, Spark will be able to recover tens of times more data from such a drive before it crashes in comparison with software-only solutions.
Low recoverability
Drive makes clicking noises right after spinning up and does not identify in the BIOS.
Hard drives with this symptom will usually have serious mechanical damage. Such cases will most commonly require a swap of the read/write heads by an experienced professional as a step in the recovery process.
Drive cannot spin up and does not identify in the BIOS.
If the drive does not make any noises at all then most likely the printed circuit board (PCB) had an electronic failure. It could be as straight forward as the short circuit protection (TVS or fuse) being triggered, or it could be a more complex electronic failure, for which the whole PCB will have to be swapped. Our team would be happy to provide guidance for this procedure as a part of technical support. If the drive makes some unusual noises then that points toward a mechanical failure. For example the read/write heads being physically stuck to the platters, or a total failure of the motor.